The following is an attempt to bring some Flow-Based Programming (FBP) concepts down to first principles... and to try to explain why I keep harking back to the difficulty of implementing FBP without multithreading, and why I suggested to Tom (Young) that we need to add this attribute to his FBP spreadsheet. This article may ramble a bit as my thinking changed a bit as I was writing it! :-) Feel free to come up with counterexamples!
Granted, I am only familiar with a few of the modern programming languages, but I believe that any language which supports threads can support "classical" FBP.
My contention is that there is one essential feature that is needed to support FBP, and that is multiple stacks... In multithreading languages, every thread has its own stack, so these languages aren't a problem. Although the basic requirement is multiple stacks, you need to be able to switch between them within the language, so you really need some kind of multithreading support. So, I have implementations among my GitHub repos for Java, C#, and C++ (using Boost) which in turn supports Lua, and probably there will be others in the future. What would have been nice would have been a multithreaded JavaScript: my JS FBP implementation is based on multiple-stack support for JS by Marcel Laverdet called node-fibers (now "Fiber"), but node-fibers doesn't really fit with the main thrust of JS, and may disappear before it can be widely adopted - see below.
What is rather strange is that two of the most popular FBP-like approaches (to use Joe Witt's suggested term) - NoFlo and Node-RED - are both based on JS, a programming language which IMHO is inappropriate for FBP. JS has Worker threads and Shared threads (?), but it seems that using them would result in prohibitively slow performance. In an article talking about Worker threads by Alberto Gimeno, there is a section entitled "Why we will never have threads in JavaScript". There is also a longish discussion on JSFBP Issue #14.
While I deeply appreciate Henri Bergius' proselytizing skills for putting many of the concepts of FBP on the map (something I never seemed able to do!), it bothers me that NoFlo is still so deeply rooted in the von Neumann paradigm. Without multiple threads, both systems (NoFlo and Node-RED) take a rather convoluted, von Neumann-ish approach to providing some, but not all, of the capabilities of FBP: configurable modularity, asynchronism, separation of concerns between components, but not well-defined lifetimes and ownership of data chunks... The fact that neither of these systems allow more than one input port per process, and also allow one-to-many connections, suggests that the choice of language trumped FBP thinking.
I do understand why von Neumann thinking has such a hold on the IT industry, despite its shortcomings. The thinking goes something like this: "Since the von Neumann architecture can do anything, any problems I have building or maintaining my app must have to do with my own shortcomings, not those of the architecture...", and maybe, "What other way is there to design a computer?" - I remember that, in the early days of computing, we were more open to other architecture possibilities... I would much rather have ("real") FBP be the first paradigm that people encounter when coming into the field for the first time, followed by procedural code, rather than the reverse. Our experience with FBP is that it is most readily accepted by people who are not brain-washed by traditional, von Neumann, thinking or people who have so much experience with it that they have become frustrated with it - this is described exactly in Kuhn's "The Structure of Scientific Revolutions". My personal experience supports this, as my first DP environment wasn't even computer-based: it was IBM's Unit Record, which was, as I say in my book, much more similar to FBP than to conventional programming. As a number of people have said, this means that you have to catch the kids young - before they have time to pick up bad von Neumann-ish habits! Maybe a Scratch-like product that is explicitly Flow-Based. At the very least, as Tom says, FBP should be part of every CS curriculum - you mean, it isn't...?!
The basic problem, as I have always viewed it, is that "real" FBP is an industrial metaphor: individual machines connected by conveyor belts, so each "machine" has to maintain its own internal context. What good would it do if the bottle capper had to share time and resources with the filling machine?! Much of the power of FBP comes from the fact that these contexts cannot interfere with each other. How do you ensure that? IMO the only way is to let each process have its own state, represented by its stack: in multithreaded environments, this happens automatically because each thread has its own stack, and you can switch easily between threads. Without multithreading, but with multiple stacks, you have to resort to hardware-dependent code to switch stacks - you can see an example of this in Switching Stacks . Without multithreading or multiple stacks, things get pretty convoluted! JS gurus have managed to find ways to do some FBP-like things, but they ain't easy!
On the other hand, to support multiple cores and shared storage, I admit you do need some fairly complex locking... but this happens under the covers, and is invisible to the user when using FBP, as it all happens in the infrastructure. Components in FBP just see "send"s and "receive"s. This architecture is called "red threads", and seems to lend itself naturally to "real FBP". So, my implementations of FBP on Github except for JSFBP are all "red" thread implementations - "Real FBP" implementations.
Now, going back in time a little: We developed the first production FBP system, called AMPS, back in the early '70s, and it was in continuous production use for at least 40 years. It was written in IBM's HLASM, and, yes, it had multiple stacks. However, it used "green" threads, so context switches only occurred at service calls, rather than potentially occurring between any pair of instructions, and all I/O was asynchronous (courtesy of IBM software), so no complex locking was required. This was perfectly adequate for production, and indeed AMPS applications performed better than applications written using conventional, synchronous, technology, mainly because a non-FBP program could be held up while a single I/O request was going on (this could even happen with QSAM!), while with AMPS you could have any number of I/O requests proceeding concurrently.
So as long as you have multiple stacks, "green" threads work very well on one core... In this approach, you have a "future events queue", where you park contexts that are waiting to execute. This is in fact how simulation systems work...
I used this approach for my JavaScript implementation (JSFBP), using Marcel Laverdet's "node-fibers" (now apparently called "Fiber"). This works very well on one core, and it's a nice simple mental model, perfectly in line with "real FBP". On the other hand, when you don't have multiple stacks, there is another restriction on FBP-like JS implementations: I think it's called the "top frame" limitation - it means that you can only send or receive in the top frame of the process. Clearly, if you allowed sends and receives from a lower level in any stack, you would have to maintain the state of all levels above it... That's a non-problem when you have multiple stacks...
However the liftetime of JSFBP is probably limited: Marcel warns that node-fibers may suddenly stop working due to the complexity of the NodeJS ecosystem. Chris Hawkes in "Why Programmers Hate the JavaScript Ecosystem" has pointed out the huge number of dependencies that get dragged into a JS application. I notice that JSFBP has waaay more PRs (133) and commits (681) than any of my other implementations (very few of them due to my enhancements or bug fixes), mainly because of almost continuous enhancements to eslint, vulnerabilities in indirectly dependent JS packages, etc., etc.
On the other hand, JavaScript is still popular, possibly because it's the language du jour, and/or because it plays nicely with HTML5, and people seem to want the server and client languages to be the same... What's so difficult about learning more than one language?!!! Look at JavaFBP-WebSockets, which uses JavaScript in the client and JavaFBP in the server, so both languages play to their strengths!
If you look at TIOBE, JavaScript is still at #7, while Java is #2, having changed places with C over the last year. IMHO JavaScript is never going to make it much above #7. I was relieved to learn recently that, like me, large numbers of people cordially dislike JavaScript, so maybe we can agree to let the JS-based FBP-like systems wither away, at least with respect to long-running batch or servers, and switch to more productive threads-based "real FBP" implementations...
It may seem strange that I am saying that batch jobs (and servers) need multithreading, considering that there were handled for years by control-flow von Neumann programs... but they were (are) very hard to maintain, and couldn't take advantage of multiple cores. It starts to make more sense if you think of a program built using FBP as a simulation of a factory that processes data, rather than bottles... Threads are a bit of a blunt instrument - basically for FBP the basic requirement is to have multiple stacks and a way of switching between them. However, threads let us take advantage of multiple cores, which will become increasingly important over the next few years, and it also gives us multiple stacks... for free!
Because of their control-flow orientation, FBP-like implementations also usually can't handle more than one input port on a process - the originator of Node-RED told me "he hadn't run into that requirement yet"! John Cowan says the following with respect to this architecture: "...each component is controlled by its upstream partner(s) rather than being autonomous. " See the discussions in FBP-inspired vs. "real FBP" and Concatenate component. As I have said many times before, "real FBP" is a real paradigm change, and you need to leave your von Neumann habits at the door - or better still, never have learnt them! Meanwhile, we have JavaFBP, C#FBP, and CppFBP, and probably more multithreading languages to come - I know many people are working on FBP implementations, in particular for Python - see FBP implementations in Puython, which I would expect (hope) mostly use multithreading!
The article Concurrent and Parallel Programming Languages, and especially Multithreaded languages, gives a huge list of languages supporting multithreading, so hopefully one of these will be the next JavaScript... From this list, Clojure, Go and Rust seem to be creating the most buzz! Clojure is interoperable with Java - OTOH we already have JavaFBP, so why bother with Clojure unless you want LISP-like constructs. Elixir?
Last comment: diagramming data flow is different from running it! Duh! DrawFBP could easily be extended to support any number of FBP implementations, including "FBP-like"... and presumably, with some tweaks, the diagramming tools for FBP-like systems could be extended to support "real FBP" implementations...
That is enough for now (too much, probably!) - sorry about the rant!
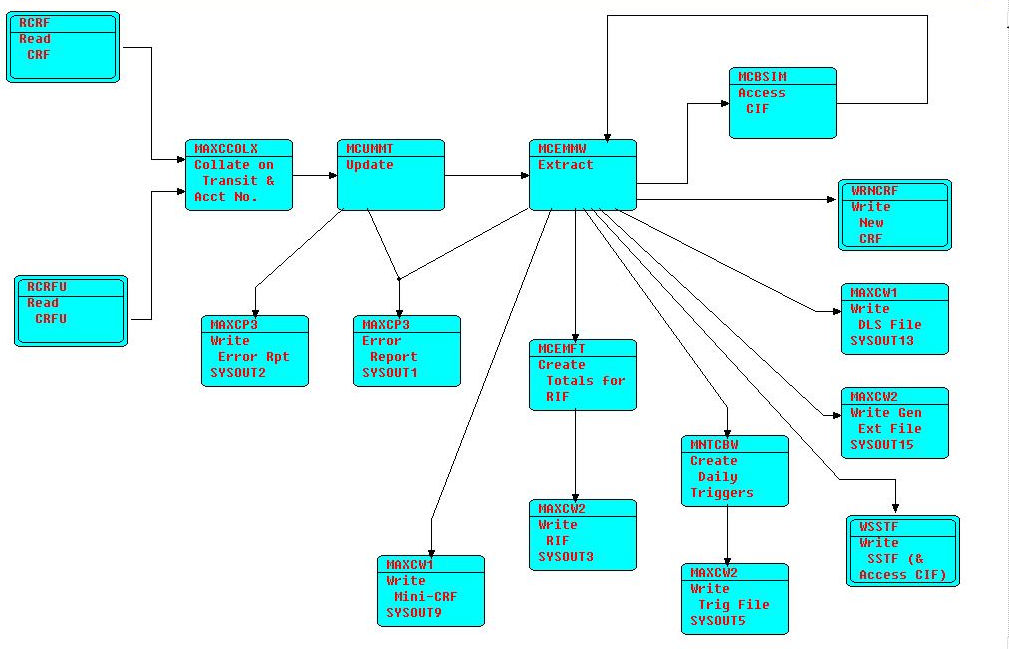
Here is a picture of one third of an AMPS production application, coded in the '70s, and processing millions of transactions every night for 40 years - worked like a charm, and was continuously maintained to support changing requirements during all of that time, in many cases by kids who weren't even born when it went into production! Any FBP implementation should be able to run this diagram - that could be a litmus test!